主要介绍了Python自定义scrapy中间模块避免重复采集的方法,实例分析了Python实现采集的技巧,非常具有实用价值,需要的朋友可以参考下
”Python 自定义 scrapy模块 重复 采集“ 的搜索结果
from scrapy import logfrom scrapy.http import Requestfrom scrapy.item import BaseItemfrom scrapy.utils.request import request_fingerprintfrom myproject.items import MyItemclass IgnoreVisitedItems(obje...
from scrapy import logfrom scrapy.http import Requestfrom scrapy.item import BaseItemfrom scrapy.utils.request import request_fingerprintfrom myproject.items import MyItemclass IgnoreVisitedItems(obje...
文章目录Scrapy 框架一、 简介1、 介绍2、 环境配置3、 常用命令4、 运行原理4.1 流程图4.2 部件简介4.3 运行流程二、 创建项目1、 修改配置2、 创建一个项目3、 定义数据4、 编写并提取数据5、 存储数据6、 运行...
本文实例讲述了Python使用scrapy采集数据过程中放回下载过大页面的方法。分享给大家供大家参考。具体分析如下: 添加以下代码到settings.py,myproject为你的项目名称 复制代码 代码如下:DOWNLOADER_...
Scrapy 是用 Python 实现的一个为了采集网站数据、提取结构性数据而编写的应用框架。常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定...
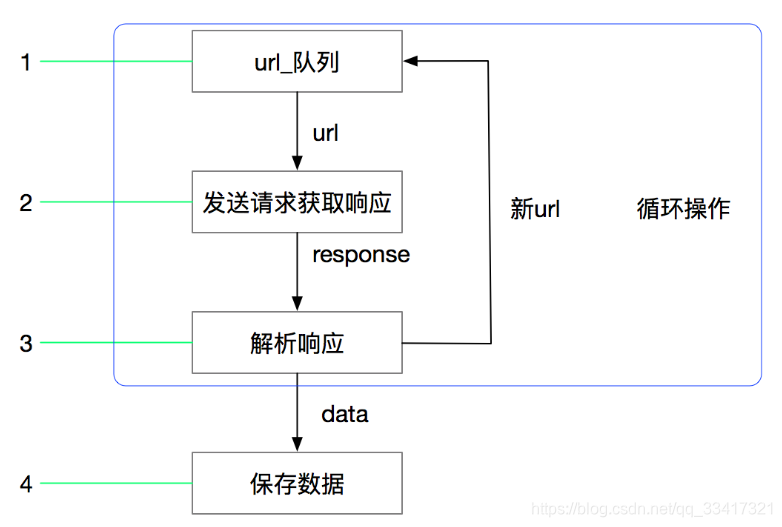
python引入不同文件夹下的自定义模块方法初学Python,这个问题搞了我好久,现在来分享下我的解决思路,希望可以帮到大家。先说下python引入模块的顺序:首先现在当前文件夹下查找,如果没有找到则查找Python系统变量...
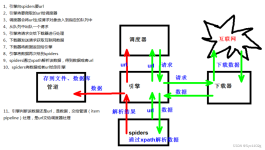
Scrapy是一个基于Python的Web爬虫框架,可以快速方便地从互联网上获取数据并进行处理。它的设计思想是基于Twisted异步网络框架,可以同时处理多个请求,并且可以使用多种处理数据的方式,如提取数据、存储数据等。本...
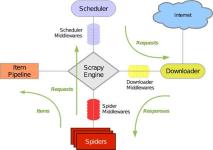
一、Scrapy框架简介Scrapy是用纯Python实现一个为了爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛。利用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,...
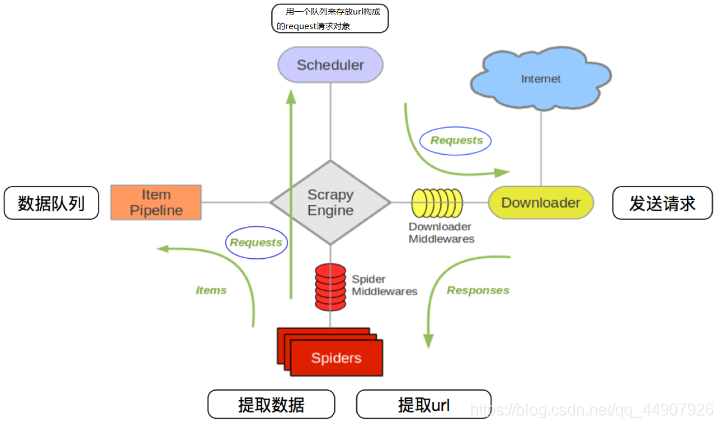
scrapy自动翻页采集,第二页跳转后,爬虫自动结束# -*- coding: utf-8 -*-import scrapyfrom weather.items import WeatherItemfrom scrapy.http import Requestclass WeatherSpider(scrapy.Spider):name = ...
这一节将继续学习scrapy的另一个组件-pipeline,用来2次处理数据(本节中将以储存到mysql数据库为例子)虽然scrapy架构下,可自定义的模块很多,其实实现一个完整的scrapy爬虫,仅仅只需要我们写好spider和pipeline,...

scrapy作为一款强大的爬虫框架,当然要好好学习一番,本文便是本人学习和使用scrapy过后的一个总结,内容比较基础,算是入门笔记吧,主要讲述scrapy的基本概念和使用方法。scrapy framework首先附上scrapy经典图如下...


原标题:Python 爬虫:Scrapy 实例(一)1、创建Scrapy项目似乎所有的框架,开始的第一步都是从创建项目开始的,Scrapy也不例外。在这之前要说明的是Scrapy项目的创建、配置、运行……默认都是在终端下操作的。不要...

Scrapy 是一套基于Twisted、纯python实现的异步爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,相当的方便~ 整体架构和组成 Scrapy Engine(引擎) 引擎负责...
一、Scrapy框架简介Scrapy是用纯Python实现一个为了爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛。利用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,...
scrapy模块01
标签: python
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。 Scrapy 使用了Twisted['twɪstɪd]异步网络框架,可以加快我们的下载速度。 Scrapy文档地址:...
最近自己用一个python里面非常常用的爬虫框架scrapy爬取豆瓣Top250电影榜单的一些数据,具体过程如下: 首先提前下载好一些库,最主要的是scrapy和selenium 第一: 开启一个scrapy项目,创建scrapy项目需要在命令行...

一、Scrapy框架简介Scrapy是用纯Python实现一个为了爬取网站数据,提取结构性数据而编写的应用框架,用途非常广泛。利用框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,...
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。它是很强大的爬虫框架,可以满足简单的页面爬取,比如可以明确获知url pattern...
第一部分爬虫架构介绍 1.Spiders(自己书写的爬虫逻辑,处理url及网页等【spider genspider -t 指定模板 爬虫文件名 域名】),返回Requests给engine——> 2.engine拿到requests返回给scheduler(什么也没做)...
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地